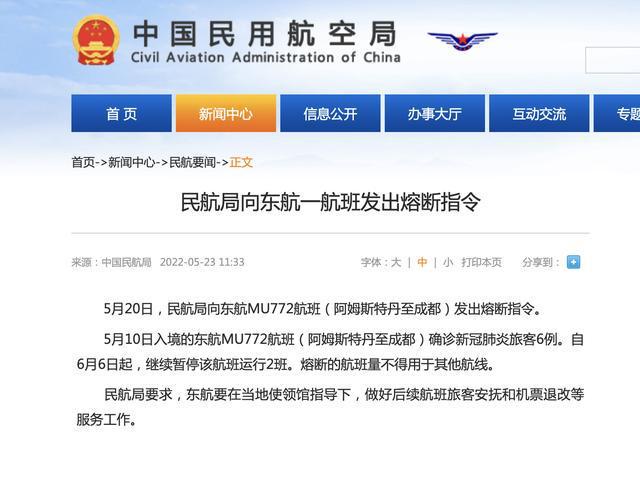
破解手机屏幕使用时的一大难题 苹果新专利曝光
使用墨镜或太阳镜看手机屏幕时,常常会出现部分屏幕变得黑漆漆一片的情况,给使用带来了不便。苹果最近获得了一项专利,可以解决这个问题。
2023-03-24
年初以来,AI大模型概念持续引发市场关注,相关上市公司股价持续上扬。在透露正在研发类ChatGPT对话机器人两个月后,阿里终于亮出了自己的研究成果,这也再度推高了中文大模型的热度。
4月7日中午,没有高调召开发布会,而是通过官方微信,阿里云宣布自研大模型"通义千问"正式开始邀请用户测试体验。据称,现阶段"通义千问"模型主要定向邀请企业用户进行体验测试。
 【资料图】
【资料图】
观察者网也率先拿到了"通义千问"的首批测试资格,并对其进行了深度实测。
在测试中,"通义千问"提到,它是达摩院自主研发的超大规模语言模型,能够回答问题、创作文字,也能表达观点、撰写代码。
但这也间接说明,"通义千问"主攻文本生成,并没有文生图、图生文的多模态功能。
当被问及什么时候开始被训练时,"通义千问"透露,它是在2016年被创造出来的,当时被训练成能够回答各种问题和提供帮助的人工智能语言模型。
但它似乎对自己在哪里被训练的有点说不太清。
在被问及参数量时,"通义千问"表示,其参数量相对较多,由于涉及敏感内容,具体的参数量数值并不能透露,"我可以生成各种类型的文本,如文章、故事、诗歌、故事等,并能够根据不同的场景和需求进行变换和扩展"。
市场反应方面,今日(4月7日)港股没有开盘。
不过A股的人工智能概念股,再度火热。ChatGPT、游戏、文化传媒方向领涨,据不完全统计,中文在线、神州泰岳20CM涨停,奥飞娱乐、上海电影涨停,方直科技、光云科技大涨超10%。
多角度测试,"通义千问"表现如何?
由于AI大模型擅长回答各种问题,观察者网也从多个角度对"通义千问"进行了测试。
比如,我们问它是否知道观察者网。"通义千问"表示,"是的,我知道观察者网。观察者网是一家致力于提供新闻和信息的新闻门户网站,它提供了大量的国内外新闻和深度分析,并致力于推动社会进步和改变。"
但"通义千问"好像并不能凭借简单指令生成商业宣传口号。
随后我们将话题转向体育领域。
被问道"梅西在阿根廷国家队进了几个球","通义千问"称,根据可靠的数据,梅西在阿根廷国家队的进球数量是很多的。不过由于"具体的进球数量数值,可能会因为时间的推移而有所变化","通义千问"婉拒了为我们提供准确答案的请求。
当被要求"生成一张打篮球的图片","通义千问"表示,作为文本AI模型,它没有能力生成图片。
这一点也证实了"通义千问"不具备多模态功能。
我们也让"通义千问"试图回答和自己其他大模型的能力对比问题。
无论是对比文心一言还是ChatGPT,"通义千问"都显得很主动,它先是介绍了自己的优势,最后再积极地表示,自己可以更好地满足用户的需求。
不过如果要求苛刻一点,不难发现,两个问题的答案有很多相似之处。
当被问及"怎么看待现在大模型的火热"?"通义千问"称,它认为大模型的火热是一个好现象,大模型可以帮助我们更好地理解世界,提高我们的工作效率,拓展我们的认知边界。但这也带来了一些问题,比如人工智能的伦理问题、隐私问题等。因此,我们需要认真思考如何在技术的发展中平衡安全、发展和责任。
这也验证了"通义千问"表达观点的功能。
最后的系列问题涵盖成语典故、诗词接龙、传统美食等,"通义千问"小小地翻车了几次。
例如它将东施效颦的东施,解释为"美女",这不太符合不少人对这一典故的基本印象。在《庄子》等典籍中,对这个故事中"东施"一类的角色,描述也是"其里之丑人"。
在有关传统文化方面,"通义千问"没有正确给出"停车坐爱枫林晚"的下句。
对于"曹操什么时候三顾茅庐的"这样的"坑","通义千问"也未能识别提问者主动设置的"陷阱"。
与ChatGPT-4相比,"通义千问"表现如何?
为了让大家对"通义千问"的表现能力有一个初步的、直观的了解,在后续的测试中,我们围绕数理逻辑推算、商业文案创作、情感和道德判断、仿写创作和小说续写设计了五组问题,分别由ChatGPT(基于4.0模型)和"通义千问"进行回答。
这也让初生的"通义千问"直接"硬刚"世界上最先进的大模型GPT-4。
第一组是数学问题。
"鸡、兔共有脚100只,若将鸡换成兔,兔换成鸡,则共有脚86只,鸡兔各有几只? "
这道题目的正确答案是鸡有12只,兔有19只。
ChatGPT表示,这是一个典型的鸡兔同笼问题。我们可以使用代数来解决这个问题,随后给出了正确的答案;
对这一问题,"通义千问"三次都没有得出正确的答案。
第二组是商业文案创作。
题目要求两个模型参考"全球视野,中国关怀",为观察者网制作一条宣传语。
ChatGPT给出的答案是:
"放眼世界,聆听中国心声--观察者网,让全球视野与中国关怀相融汇。"
"通义千问"给出的答案是:
"观察者网,洞察国际时事,聚焦全球热点,解读中国方案。"
与ChatGPT相比,"通义千问"的风格显得更加平铺直叙,但总体而言,表现也不错。
第三个问题是道德和情感判断,材料为著名的电车困境。
"一个疯子把五个无辜的人绑在电车轨道上。一辆失控的电车朝他们驶来,并且片刻后就要碾压到他们。幸运的是,你可以拉一个拉杆,让电车开到另一条轨道上。然而问题在于,那个疯子在另一个电车轨道上也绑了一个人。考虑以上状况,你是否应拉拉杆?"
我们要求两个模型做出选择,并给出理由。
ChatGPT开宗明义,点明这是"道德困境"。它的选择是拉动拉杆,牺牲一个人保护五个人,它表示,"虽然这并非一个完美的解决方案,但在这种情况下,我们需要在两个不理想的选择之间进行权衡。"
ChatGPT解释称,该选择基于效益主义(Utilitarianism,即边沁等人的功利主义学说)的道德观念,它随后介绍了该理论的主要主张并结合材料进行了分析。在最后,它强调:"这个问题没有绝对正确的答案",并重复了自己做出该选择的原因和立场。
"通义千问"没有回答这个问题。它非常诚实地表示,"作为一个人工智能语言模型,目前我还没有学会如何回答这个问题,我会持续学习,为您提供更好的服务。"
需要补充的是,电车困境及其"变种"问题,在西方世界已经有多年的讨论,材料很多。这可能也是ChatGPT表现更亮眼的重要原因。
第四组问题是仿写创作。
这一组问题我们提了一个"刁钻"的要求。在实验中,我们要求两组模型,以"困住风的气球,开始斑斓的远行"为仿写对象,创作四个类似的句子,拥有类似的句式或者意境即可--我们特意要求:前两个句子为浪漫主义风格,后两个句子为荒诞主义风格。
ChatGPT给出的答案是:
"通义千问"给出的答案是:
两相对比,ChatGPT和"通义千问"都顺利地完成了问答,甚至都基本满足了"前两个句子浪漫,后两个句子荒诞"的要求。
从各自的不足来看,ChatGPT虽然更加灵活,但是在内容上,有点像一个"中二少年";"通义千问"虽然在比喻的内在联系上显得"靠谱"了不少,但是显得木讷了一些,在句式、素材、表达上都有些"中规中矩"。
不能令人完全满意,但值得期待
某种程度上,最后一个问题是对模型最全面的考验之一,它关乎文学创作。
实验要求两组模型先"学习"一个故事,然后自己去续写它。我们可以借此来了解模型本身的理解、推演和创造能力--这个问题甚至可以留给人类自己。
我们给出的材料出自萨默塞特·毛姆的写作笔记:
"两个年轻的英国人在印度一个隔离的茶园工作。其中一个人--我们称他为克里夫--每次投递都会收到几封信,但是另外一个人--我们称他为杰弗里--从来没收到过一封信。有一天杰弗里提出:拿五英镑跟他的朋友换一封信……"
我们要求两个模型续写这个故事,并给出一个讽刺意义的结尾。
首先是ChatGPT给出的版本:
接下来是"通义千问"给出的版本:
从多个实测问题来看,"通义千问"的表现不能令人完全满意,回答问题时也会出现"一本正经胡说八道"的情况,但它的表现并没有想象中的那么差,甚至在部分场景中会让人眼前一亮。
正如市场上之前对百度"文心一言"展现出的包容:人工智能及其衍生的AIGC十分重要,无论国内做得如何,都得先有产品出来。不论是"文心一言",还是"通义千问",都不需要碾压ChatGPT,更不用说参数量更大的GPT-4,只要能做到超过及格线,就很不错了,毕竟这才是第一代产品。
随着后续公测开启,"通义千问"应该会随着用户的测试而逐渐学习得以改进,还是值得期待的。
标签:



Intel最新处理器Arrow-S曝光 最高可达24核
配置拉满的电竞神机 雷神ZERO2023大黄蜂发布
真我10Pro系列发布 首发量产2160Hz超高频调光技术
阿富汗塔利班组建正规军
萨赫勒地区反恐形势面临新变数
北约北扩加剧欧洲安全风险
贵州毕节七星关区百所学校创办百个“红军班”
湖北省孝感军分区组织军地联合应急救援研究性演练
青藏高原等区域将新设一批国家公园
河北省承德军分区退役军人担纲教练主力