破解手机屏幕使用时的一大难题 苹果新专利曝光
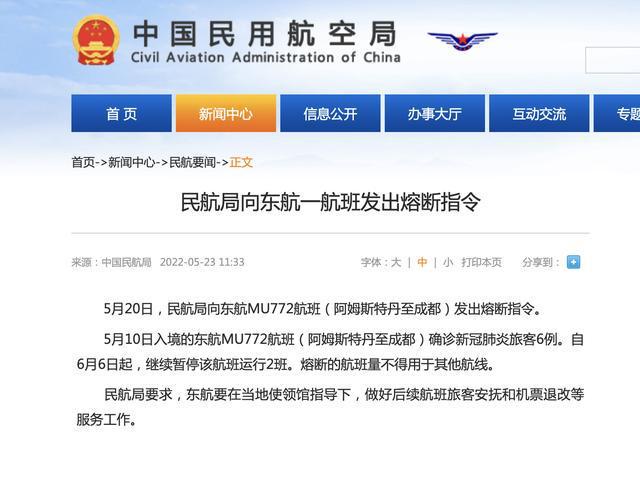
使用墨镜或太阳镜看手机屏幕时,常常会出现部分屏幕变得黑漆漆一片的情况,给使用带来了不便。苹果最近获得了一项专利,可以解决这个问题。
2023-03-24
2023年亚布力论坛夏季高峰会于8月24日~27日在深圳召开。360集团创始人、董事长周鸿祎出席并演讲。
周鸿祎在演讲中谈到,OpenAI之路不一定完全适合所有企业的发展,如果企业真的用OpenAI的ChatGPT,会发现它有很多问题。
 (相关资料图)
(相关资料图)
第一,它是万金油,无所不知,但是真的问它行业深入的问题就开始绕圈子回答,说明它缺乏行业深刻的理解。
第二,OpenAI也好,网上通用的大大模型也好都是拿通用的数据集进行训练,它对你的企业更了解吗?它做一些通用的办公、写作可能还可以,但是只要跟企业业务一结合深了,发现它并不了解你的企业。
不仅如此,还有数据泄露问题,“你为了提出很多要求,把你企业的很多数据传给它,但是这些数据可能就会导致企业数据的泄露”。
第三,成本问题,ChatGPT4号称训练一次的成本高达2千万美金,最近开始训练ChatGPT5了,要训练一个万亿的模型,就是一个天文数字,这样的话人工智能离所有的产业界和企业界就非常远。
他表示,人工智能是一场工业革命,但工业革命不会自然发生,就像电脑什么时候产生了工业革命?电脑刚发明的时候没有工业革命?因为少数精英团队才在用,个人电脑被发明之后,电脑走下神坛,每个企业都买得起电脑了,这个革命才产生。
所以,周鸿祎提出,中国还有另外一条路,美国今天也在往这条路上发展,就是把大模型拉下神坛,换句话说,能不能把大模型做小。
在他看来,行业化、企业化、专业化、垂直化,大模型很了不起,但是企业里边实际上是招了很多大学毕业生,在不同的垂直领域进行培养,有的人懂财务,有的人懂营销,大家是团队作战。
所以,周鸿祎表示,非常反对一个观点,说大模型是操作系统,这样隐含的产业发展,全世界大模型只会最多三套,可能就两套,就被垄断了。
“我觉得大模型更像电脑的发展,以后每个企业根据自己的应用场景,可能都有若干套大模型。”他说。
所以,周鸿祎表示其中有几个关键点:
第一,把大模型做垂直、做专之后,它对企业更了解,它在公有大模型的基础之上再加入我们企业内部的很多知识的训练,
第二,现在大模型,包括国内还有开源的能力,对企业来说就够用了,现在企业就可以探索结合自己的场景。
第三,大模型做小了之后,大模型不一定在云端,可以在终端,可以在边缘。
全世界现在也出现这个趋势,就是怎么把大模型做小,做小了之后,因为它只解决垂直领域的问题,它的参数不一定要万亿,不一定要千亿,事实上今天很多开源的软件给的是百亿的模型,百亿跟ChatGPT不能比,但是在企业内部够用的时候,它就能把这个成本从原来的千万美金降到部署成本是千万人民币甚至百万人民币的级别,这个目标就真正达到了,就把大模型拉下神坛,在座的诸位可能都有若干自己的大模型,这条方法在现阶段可能是在等待我们中国自己的算力突破之前,你可以认为是一个游击战。
“所以,只需要少数的公司用大规模的投入把基础模型训练出来,提供给很多企业,企业用小规模的算力就能够进行微调,然后用小规模的算力进行部署,来进行推理和计算,在现阶段这样一算,可能目前的A100、A800再加上国产华为的910B,可以在一定阶段满足我们国家的需求。”他说。
周鸿祎认为,我们在原始创新上有点落后,这需要时间去追赶,但是我们人口众多,企业众多,场景众多,比如深圳就有几十万家企业,如果都训练出来自己的小规模的大模型,大模型无处不在,这里会产生很多产业创新的机会。
责编:刘安琪 | 审校:陈筱娟 | 审核:李震 | 监制:万军伟
标签: 周鸿祎



Intel最新处理器Arrow-S曝光 最高可达24核
配置拉满的电竞神机 雷神ZERO2023大黄蜂发布
真我10Pro系列发布 首发量产2160Hz超高频调光技术
阿富汗塔利班组建正规军
萨赫勒地区反恐形势面临新变数
北约北扩加剧欧洲安全风险
贵州毕节七星关区百所学校创办百个“红军班”
湖北省孝感军分区组织军地联合应急救援研究性演练
青藏高原等区域将新设一批国家公园
河北省承德军分区退役军人担纲教练主力